


Hace algunos años tuve la ocasión de participar en un proyecto de Datawarehousing con la solución SAP BW en un cliente del sector retail alimentación, la arquitectura que tenían era un BW 7.0 con base de datos Oracle. Como podéis imaginar, las volumetrías eran bastante altas por lo que había que hilar muy fino en lo relativo al modelo de datos y aplicar las opciones que había en ese momento para tener un rendimiento entre aceptable y bueno (compresión, particiones, agregados y unas queries orientadas a rendimiento).
Uno de los procesos que había definidos era la creación de segmentos de clientes basados en segmentación RFM que en ese momento se implementó con funcionalidad de BW y con reglas estáticas para el cálculo de los segmentos; así que en este post vamos a ver un enfoque para realizar una segmentación RFM con un dataset demo pero empleando funcionalidad nativa de Hana.
En este post con la primera parte os cuento el modelo físico, lógico y el approach con Hana AFM
Parte I: El modelo y RFM empleando Hana AFM
Antes de nada empecemos por el principio.
¿Qué es una segmentación RFM?
La segmentación RFM es una técnica muy popular de marketing que permite segmentar a los clientes en grupos con un comportamiento homogéneo analizando el histórico de compras con el objetivo de establecer campañas o acciones adaptadas a las características de cada grupo.
Se establecen 3 ejes de análisis:
- Recencia (R): Como de reciente es la visita o compra del cliente (Fecha de la última compra).
- Frecuencia (F): Volumen de transacciones de compra (Número de transacciones).
- Monetario (M): Importe de las compras (Importe).
EL RFM permite responder por ejemplo a preguntas del tipo:
- Quiénes son tus mejores clientes.
- Clientes susceptibles dejar de comprar (churn).
- Qué clientes nos interesa retener y cuáles dejar marchar (Principio de Pareto aplicado a ventas y marketing).
- ….
Vamos a echar un vistazo al funcionamiento de una segmentación RFM. Dado un dataset con histórico de ventas por cliente.

Establecemos unos intervalos agrupando los valores individuales, normalmente 5, para segmentar cada uno de los 3 ejes. El valor 5 representa el segmento con la compra más reciente (R), con mayor frecuencia (F) y con mayor valor monetario (M) mientras que el valor 1 representa el segmento con la compra más antigua (R) con la menor frecuencia (F) y con el menor valor monetario (M).

Finalmente determinamos el segmento RFM concatenando el valor de cada segmento individual y calculamos el score.
Score = (R + F + M) / 3


Vamos a echar un vistazo a los elementos que serán necesarios en nuestro ejemplo.
- El modelo de datos físico: Las tablas con el dataset cargado.
- El modelo de datos lógico: Modelo de vistas con los cálculos y relaciones. La idea de este modelo es que de servicio a reporting y sirva de base para el cálculo del RFM.
- Hana PAL para creación de los segmentos.
- Hana DSI (Smart Data Integration) para persistencia.
- Herramienta de BI para visualización.
Modelo de datos físico
El modelo de datos del que partimos tiene un conjunto de tablas donde una de ellas contiene los datos transaccionales de los tickets de venta a nivel de posición con el producto vendido y otras actúan como tablas de datos maestros (atributos y descripciones). En nuestro ejemplo trabajaremos con un total unos 31 millones de registros de datos transaccionales, 5.000 productos y 50.000 clientes.


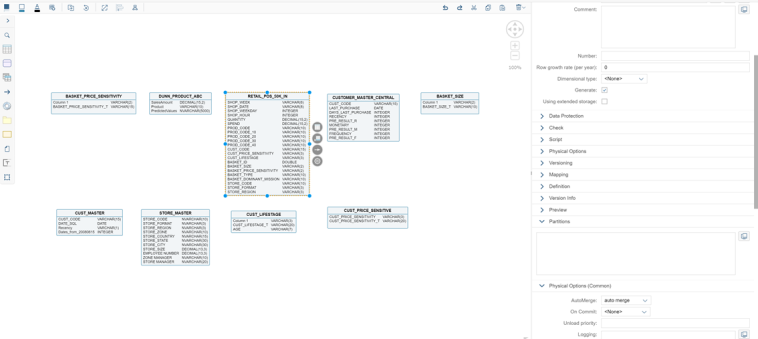
Modelo de datos lógico
Para crear el modelo de datos lógico, nos hemos decantado por la funcionalidad de Hana Modelling, creando un conjunto de vistas calculadas (calculation views) que nos ha permitido crear un modelo de datos virtual donde relacionamos las tablas, generamos KPI’s y semántica al vuelo en tiempo de ejecución.
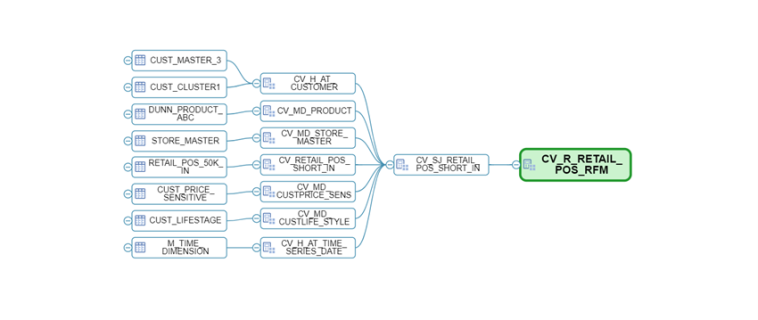
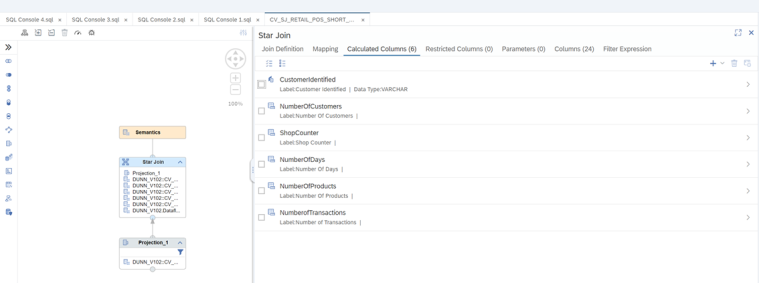
Este conjunto de vistas se encargará de proporcionarnos las métricas que necesitamos para generar nuestro análisis RFM además de permitir explotar la información desde herramientas de BI, adicionalmente tenemos una última vista donde realizamos la exposición de los campos que vamos a emplear en la segmentación (cliente, importe, nº de transacciones y días desde última compra). El detalle de cálculo de cada uno es el siguiente:
- Para la recencia: La obtenemos mediante una diferencia de fechas entre el momento de análisis y el momento de cada una de las compras. Como nos interesa la compra más reciente aplicamos un ranking para quedarnos con la 1ª compra, es decir, la más reciente.

Para la frecuencia: La obtenemos mediante un ratio que aplica un count distinct sobre el campo ID del Ticket, es decir, aplicamos un conteo para saber el número de tickets y por tanto saber cuántas veces ha realizado compras del cliente en el intervalo de tiempo seleccionado.

Para el monetario: La obtenemos a través de un ratio de tipo decimal con método de agregación sum, nos proporciona el importe de la venta en el intervalo de tiempo seleccionado.
Hana PAL (Binning) – Creación de segmentos
Para la determinación de segmentos puede ser qué directamente nos hayan especificado el número y cómo deben ser los intervalos en cada uno de ellos, en cuyo caso simplemente realizaremos la definición en la implementación conforme a esas reglas.
Por ejemplo crear 5 intervalos para el segmento monetario con los siguientes ámbitos de valores:
- De 0 – 100 — Segmento 1.
- De 101 – 1000 — Segmento 2.
- …
- De 100.000 a 200.000 — Segmento 5.
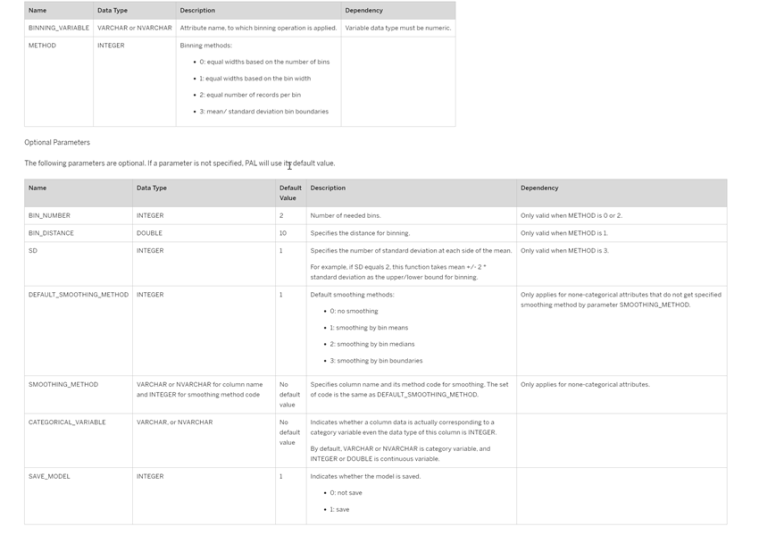
Sin embargo, como parte del ejemplo de este post, lo que vamos a hacer en lugar de definir una serie de intervalos manuales es definirlos empleando los algoritmos disponibles en el PAL de Hana, en particular emplearemos el algoritmo de Binning o discretización.
En este link (Hana Pal Binning) tenemos el detalle de las opciones que pueden aplicarse para la obtención de intervalos.
Binning Enfoque 1: AFM (Application Function Modeler)
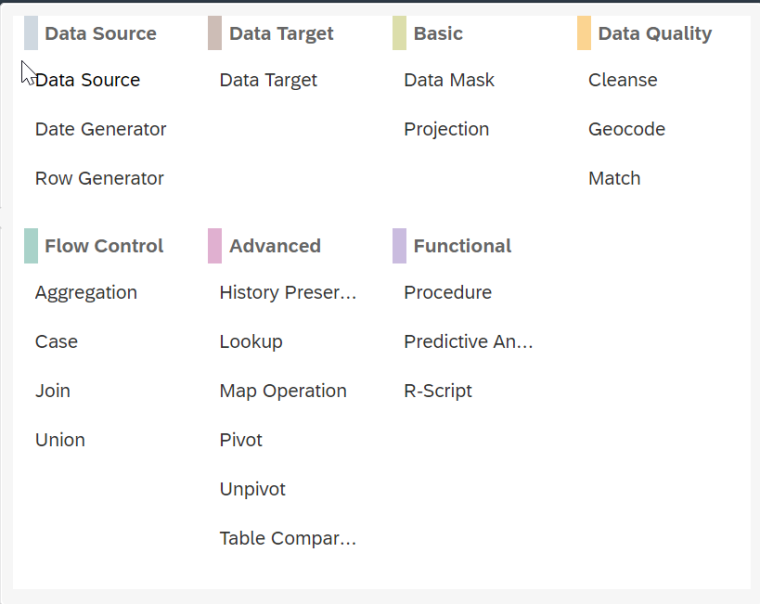
El Application Function Modeler o AFM es una funcionalidad disponible tanto en Hana Studio (XS Classic) cómo Web IDE for Hana (XS Advance) que permite crear en una serie de flujos denominados flowgraphs que se implementan de manera gráfica para modelar y tratar los datos, se selecciona la fuente, el destino y en medio disponemos de una amplia variedad de operadores. Por defecto la activación de un flowgraph genera un procedimiento en el sistema.
Algunos de los operadores que admite son los siguientes:

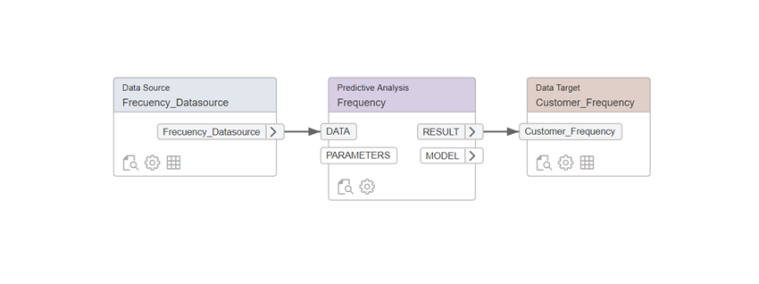
En nuestro ejemplo vamos a implementar 4 Flowgraphs para calcular el RFM, 3 de ellos nos servirán para obtener la R, la F y la M y el cuarto se encargará de unir esta información y persistirla físicamente en una tabla del sistema.
Recencia
Como origen seleccionaremos el ratio “Diferencia de días” que previamente hemos creado en la vista.

La configuración del binning es la siguiente para generar 5 bins.

Frecuencia
Como origen seleccionaremos el ratio “Nº de transacciones” que previamente hemos creado en la vista.

La configuración del binning es la siguiente para generar 5 bins.
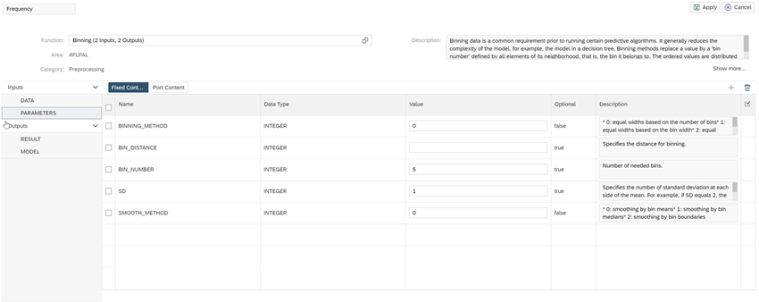
Monetario
Como origen seleccionaremos el ratio “Importe” que previamente hemos creado en la vista.
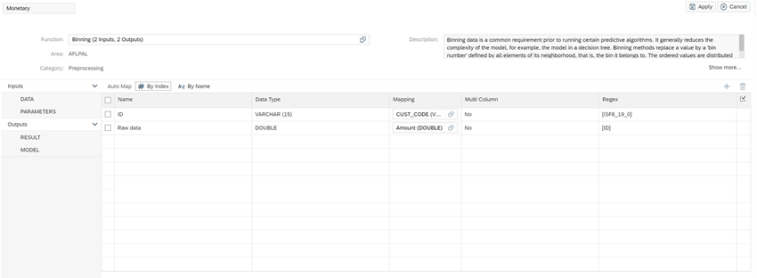
La configuración del binning es la siguiente para generar 5 bins.
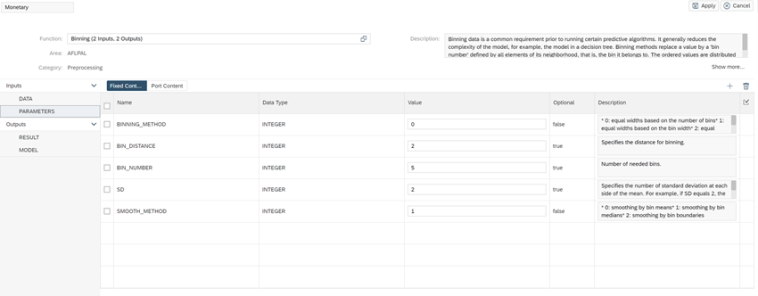
Cómo pasó final hemos implementado un último flowgraph que será el encargado de unir la R la F y la M calculadas previamente y persistirlas en una tabla en Hana.

Ejecutamos el proceso
El siguiente paso será ejecutar nuestro proceso esto podemos hacerlo de 2 maneras bien manualmente desde cada uno de los flowgraphs presionando el icono de “Execute” o a través de sentencias de SQL script.

Una vez ejecutado el proceso correctamente el aspecto qué tiene la tabla donde ya tendremos todos los clientes perfectamente categorizados con cada uno de los intervalos es el siguiente.

Llegados a este punto hemos finalizado el ejemplo para realizar una segmentación de clientes RFM empleando la funcionalidad gráfica AFM (Application Function Modeler) mediante Flowgraphs.
En el siguiente post os contaré cómo realizar la misma aproximación, pero utilizando la API de Python para algoritmos de Machine learning en Hana y algunas visualizaciones interesantes utilizando una conexión Live contra este modelo desde SAP Analytics Cloud (SAC) y así poder analizar los segmentos.